1. 什么是Template Query
在我们实际的编程过程中,我们很容易碰到printf这类需要在运行时来决定到底打印出什么的函数,例如
|
1 |
printf(“hello %s”, sth); |
在这个例子中,那个%s占位符表明了我们以后希望打印的内容格式和位置。同样,在我们书写SQL语句的时候,也会出现这样的情况,例如
|
1 |
SELECT * from tbl1 WHERE id = ??? |
我们很有可能在代码中会根据用户的输入来决定如何写入这个???。一种解决办法是,我们在程序中自己记录除了???直往外的内容,然后每次拼接出这句SQL。另一种办法就是使用MYSQL++的Template Query功能。
说到底,Template Query就是让我们省去每次去做“拼接”的过程。MYSQL++引擎会为我们做这一切事情。
2. 如何使用Template Query
- 基本用法
通过作者为我们准备的manual以及tquery*.cpp这几个示例,我们可以总结出以下两种普遍的用法。
- 方法一:利用参数传入实际值
|
1 2 3 |
mysqlpp::Query query = con.query("select * from stock where item = %0q"); query.parse(); mysqlpp::StoreQueryResult res1 = query.store("Nürnberger Brats"); |
这个用法总结起来就是先设置template,然后调用Query:: store, Query:: exec, Query:: storein等等用于执行SQL语句的方法,然后把template中的占位符的内容“依次”(这个“依次”有玄机,见下文)写入这些方法的入参。
需要注意的是,上文中的%0,%1等表示输入的参数的顺序(但是在template中,%0,%1等数字可以任意排放),这个必须和Query:: store等传入的参数的顺序匹配。
- 方法二:利用mysqlpp:: SQLQueryParms传入参数
|
1 2 3 4 5 |
mysqlpp::Query query = con.query("select * from stock where item = %0q"); query.parse(); mysqlpp::SQLQueryParms sqp; sqp << "hello"; mysqlpp::StoreQueryResult res1 = query.store(sqp); |
大体上和普通用法一致,主要的区别在于对于Query:: store, Query:: exec等执行函数的参数上,不再使用逐个输入,而是类似于流式输入一般,先将所有的内容写入到mysqlpp:: SQLQueryParms中,然后一同当做入参。我认为此法换汤不换药。但是作者认为,提供这个机制的原因在于This is useful when the calling code doesn’t know in advance how many parameters there will be. This is most likely because the templates are coming from somewhere else, or being generated.
- 方法三:默认参数
|
1 2 3 4 |
query << "select (%2:field1, %3:field2) from stock where %1:wheref = %0q:what"; query.parse(); query.template_defaults[1] = "item"; query.template_defaults["wheref"] = "item"; |
上面的两个query.template_defaults是一个效果,其中,第一个是使用了位置,第二个是使用了名字。有了这个默认参数之后,在后续的store等调用中,就不需要给这些参数进行设置了。
值得注意的是,MYSQL++的默认参数和C++的默参机制一样,都是只支持默认参数放在最后。这也就解释了为什么要为参数设置编号了(比如上面的%2:field1等)。
- 方法四:重置template query
当我们在一句template query之后,想要重新利用这个Query变量,应该如何通知MYSQL++来重用?query.reset() !
- 占位符
在作者的manual中专门有一个章节提到了占位符。我这里只是传达一下意思,
|
1 |
query << "select (%2:field1, %3:field2) from stock where %1:wheref = %0q:what"; |
上文中的%0q:what就是一个占位符。他的规范模式是这样的
|
1 |
%###(modifier)(:name)(:) |
我觉得最后一个冒号(colon)可以先行忽略,它的作用就是为了防止你的name当中出现了冒号。根据作者的解释,###是数字,modifier主要有以下几个
| 符号 | 含义 |
| % | 需要打印出% |
| “” | 告诉MYSQL++引擎不要quote和escape |
| q | 告诉MYSQL++引擎根据需要quote和escape |
| Q | 告诉MYSQL++引擎根据需要quote而无论如何不要escape |
至于那个name,我的理解就是一个助记符。因为MYSQL++支持同时用位置和名字对参数进行设置,所以这个名字就有那么点意思了。
3. MYSQL++ Template Query的实现机理
在开始真正的探索Teamplate Query之前,我们需要先从他会用到的一些帮手入手,了解一些蛛丝马迹。
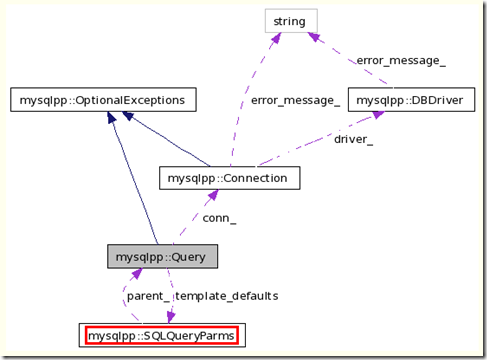
- SQLQueryParms
从作者的说明上来看,该类型的作用就是为了给Template Query做参数填入的。所以猜测该类型的功能不应该很多,更多的应该是一些辅助功能。
从实现上来看,该类型继承了vector<mysqlpp:: SQLTypeAdapter>,并重新实现了一系列的set方法(下图的代码片段中所用到的operator<<是被SQLQueryParms override的,实际上就是一句push_back)

另外,该类型还提供了对于参数的escape操作,

而上面的parent_是一个Query*类型,这个在后面讲mysqlpp:: Query构造器的时候会很容易看到的。
这个类型还有一些东西是需要关注的,主要是覆盖(overwrite,不是重载override)了std::vector的一些如operator[ ]等定位、置放的方法,举例如下

其实主要就是对于不在size范围内的索引,不是返回错误,而是进行拓展。为什么需要这么做?考虑一下template query的默认参数。如果template总共有4个占位符(params),只有最后一个param是有默参的。所以很显然,我们会有
|
1 |
my_query.template_defaults[3] = “XXXYYY” |
这样,我们就需要拓展这个template_defaults(他就是一个SQLQueryParms类型)的容量到4,而且需要把第四个元素替换成“XXXYYY”。
- mysqlpp:: Query对template query的支持
- 成员变量
我认为要理解Template Query的机制还是要从mysqlpp:: Query入手。
看实现之前,我们先来看一下一些稍后会用到的Query成员变量
|
1 2 |
// Used for filling in parameterized queries. SQLQueryParms template_defaults; |
该变量的作用就是为template query(第二种用法)的params提供一个存储空间。
以下3个变量是相辅相成的,配合起来表达的就是一个意思——提供template query(第一种用法)保存params的空间,以及其对应的名字(记得上述的占位符中的name?)和对应的位置(上述占位符中%xxx的那个xxx)
|
1 2 |
// List of template query parameters std::vector<SQLParseElement> parse_elems_; |
该变量保存变量的方式是“顺序”保存最原始的template中的表示变量的部分(%后面的部分)。例如,如果template是“select * from %2q:ParamA, %1:ParamB”,则在parse_elems_中的排列顺序就是[0]==ParamA, [1]==ParamB。
|
1 2 |
// Maps template parameter position values to the corresponding parameter name. std::vector<std::string> parsed_names_; |
该变量保存变量的方式是根据最原始的template中的表示变量的部分(%后面的部分)的真实顺序保存在对应的index下。例如,如果template是“select * from %2q:ParamA, %1:ParamB where %0q:ParamC”,则在parse_elems_中的排列顺序就是[0]==ParamC, [1]==ParamB, [2]==ParamA。
|
1 2 |
// Maps template parameter names to their position value. std::map<std::string, short int> parsed_nums_; |
这个是名字到索引的对应map。Key就是名字,而value是该parameter在parse_names_(见上面)中的位置。
|
1 2 |
// String buffer for storing assembled query std::stringbuf sbuffer_; |
- 成员函数
我们先以第一种用法进行代码解析。
|
1 2 3 4 5 6 7 8 |
mysqlpp:: Query query = con.query(“select * from stock where item = %0q”); query.parse(); // 执行方法一: query.store(“hello”); // 执行方法二: SQLQueryParms sqlQueryParms; sqlQueryParms << “hello”; query.store(sqlQueryParms); |
- 准备template query
从上面的代码,线索在于Connection:: query( )方法。

看一下Query的构造函数,其实就是把mysqlpp::Connection放入到Query自己的变量中,把qstr代表的语句放入到自己的缓存(sbuffer_)中,最后再初始化了一个SQLQueryParms变量。
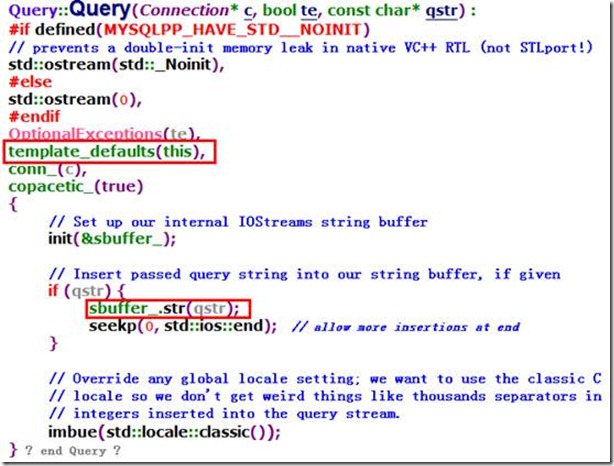
具体来看一下这个sbuffer_吧,他其实就是std::stringbuf。而这个SQLQueryParms类型的template_defaults变量的构造器调用上文在介绍SQLQueryParms的时候已经解释过了。不再赘述。
- 解析template query
Template query的关键就是Query:: parse方法,为什么每次在使用template query之前一定要调用这个方法?因为正是这个方法告诉了mysql++,你将要使用的是template query! This method sets up the internal structures used by all of the other members that accept template query parameters.
接下去的问题是,那个所谓的”internal structures”是什么?(由于代码比较长,这里只贴出来该方法的一些特别的小片段了,具体实现可以自己去看query.cpp中的Query::parse()方法实现。)
其实这个Query::parse()主要做的事情就是解析已经被保存在sbuffer_中的字符串(对的,就是刚才讲的基本的template)。至于怎么解析?关键点也在之前讲过了,就是那个占位符(%###(modifier)(:name)(:))!

其实这里的做法就是一个个字符解析,遇到了“%”表示可能遇到了占位符。记得上面讲过,如果连续两个%%,那么就表示我们需要的真的就是一个“%”而已(上面代码中的282行到285行)。
琐事略过,反正该方法查看到数字(上述代码第286行),就知道了我们填入了一个参数以后在Query:: store、Query:: exec等方法中传入的参数所对应的位置索引(就是下面代码中的num),此时他不急着去更改Query类型内部变量,而是继续找那个option。

等这些信息都有了之后,该方法做了如下工作
|
1 |
parse_elems_.push_back(SQLParseElement(str, option, n)); |
你完全可以把SQLParseElement当做一个结构体,他就是保存了一些信息(包括了在此param之前的所有语句(截止到上一个param,其实就是以形参为断点,把plain text分离,例如。。。。)——保存在str中,具体的option以及相对应的index)。
随后,parse()方法又去看了那个name。如果有的话(其实他主要看在module之后的那个冒号),解析出来之后成对地加入到Query自身的变量中。

注意,这里略去了一些不是很重要的细节。例如parsed_names_是一个vector而不是一个map,所以上面的片段之前会有根据n(即刚才根据占位符解析出来的数字)和parsed_names_.size()的比较的过程,如果n大的话,就扩充这个vector,这样做的目的其实就是为了让param在其对应的位置上(而且允许用户随意排放param位置)。
在parse()方法的最后,作者对parse_elems_做了一个标记,表示这是最后一个param。
![]()
为什么一定要多一个标志?马上来解释。
- 执行template query
上面讲到了template query的两种执行方法,其实异曲同工,殊途同归。剧透一下,最终调用的都是Query:: store(SQLQueryParms& p)。
刚才已经解析过了Query:: parse(),对于执行而言,就是Query:: store(const SQLTypeAdapter&) (或者Query:: store(SQLQueryParms& p))。
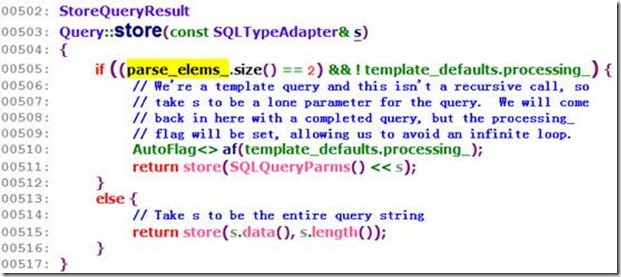
一看到这里,其实我的第一反应是,为什么505行会有这个size等于2的判断?从代码中来看,我们确实可以直接像下面这样用store.
|
1 2 |
mysqlpp:: Query query = con.query(); query.store(“select * from stock”); |
顺便说一句为什么可以有这么直白的写法,mysqlpp:: Connection有一个query方法(上面第一行代码),它的参数有默认参数
![]()
但是他的实现还是若无其事地传递给了Query

可惜Query:: Query方法会检查这个指针,如果为0,那么直接就不填写sbuffer_。
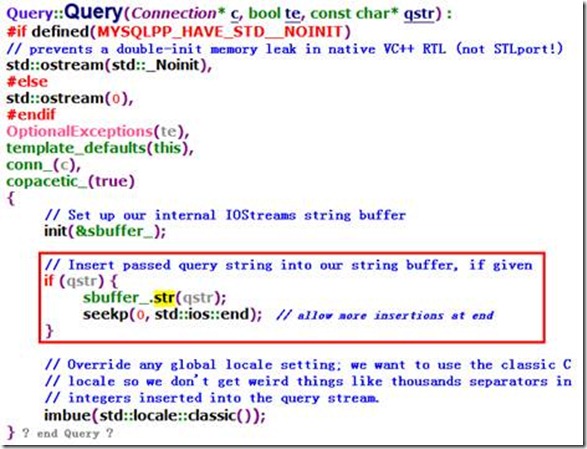
言归正传,根据上面的例子,我们可以看到Query:: Store方法既可以表示template query也可以表示non-template query。这两者怎么区别?回到Query:: store(const SQLTypeAdapter&)的源代码(为了方便,这里再展示一次)

他首先检查size。为什么是与2比较?记得之前在讲Query:: parse的最后专门会多往parse_elems_中插入一个表示结束的标记?这个标记就占了一个坑,如果是template query,那么至少还会有一个占位符,所以这个占位符又是一个坑?所以通了嘛。如果真的是template query,你又用了单参数的Query:: store(比如这里所展示的这个),那么根据用法你传入的一定就是这个param的实参。
顺便说一句,现在明着的Query::store版本只有传入单个const SQLTypeAdapter&的版本,以及传入SQLQueryParms的版本,如果你有多个params怎么利用Query:: store传入?哦!我们可以申请SQLQueryParms,然后一个个“operator << ”进来。但是从manual中可以看到,貌似是有支持多个const SQLTypeAdapter&的版本的,他们在哪里?他们应该使用perl脚本生成的。详见http://tangentsoft.net/mysql++/doc/html/userman/configuration.html#max-fields。其中的代码和这里很像,只不过那个size==2的检测变成了size==3,size==4等。
再回到我们的主线,如果调用Query:: store(const SQLTypeAdapter&)的时候其实只是想作为non-template query来处理的,那么请见介绍mysql:: Query的相关章节,我们这里只关注template query。
看到上面的代码的510行,他直接通过一个RAII机制把processing_标志置为true(当过了这个AutoFlag的作用域,这个标志会被置为false的)。然后在511行,调用了SQLQueryParms:: operator << ()方法(这也就是我为什么说两个Query:: store() 殊途同归了)。

之前介绍过,SQLQueryParms继承自vector,所以很容易理解下面的代码,需要注意的是返回值还是一个SQLQueryParms。
所以,第511行最后调用的是Query::store(SQLQueryParms& p)。那我们来看这里

又要看一下Query:: str(SQLQueryParms& p)

很好猜,这里一定对sbuffer做了什么。来看一下Query:: proc。
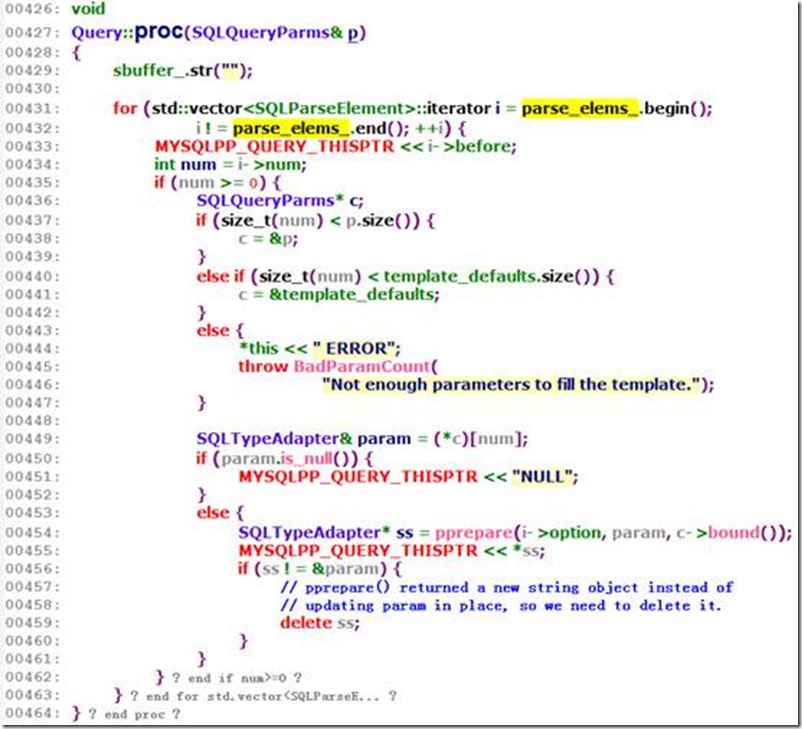
首先,他直接把sbuffer_给清空了!这里应该是要重新塑造这句query吧。然后遍历所有的parse_elems_。
注意到,在433行,MYSQL++先行将那些plain query部分(即那些固定的template)先写进自己的缓存(之前有讲过,在做parse()的时候,会根据params把证据template进行拆分,在某个param之前,前一个param之后的部分都会被插入到SQLParseElement的before变量中,方便这里的顺序拼接)。
那么436到447在干什么?想一下,template query是支持默认参数的,而且设置默认参数和设置template的语句是分开的,所以如果我们需要重新拼接query(即把template 和对应的param放到一起去)必须要有一定的机制来找到传入的实参吧,这些实参可能是传入的参数也可能是默认参数!所以这么几行的作用就是用来判断拼接语句所需要的实参到底是在哪里。
如何判定?记得在Query:: parse()中,我们根据template中的参数的看见顺序填写到parse_elems_对应位置上(例如,如果有%8q,那么在parse_elems_[7]上才存了这个变量),同时类似的概念也出现在template_defaults上,这是一个SQLQueryParms变量,他也有自动扩充的功能(见上文)。在Query:: parse()时,我们记录下了这个数字(例如,%8q中的这个8),让他与我们传入的所有参数的数量进行比较。由于我们总是假设用户给过来的顺序插入SQLQueryParms的params就是按照对应%0,%1,%2。。。的顺序来的,所以可以判定如果该数字大于传入的所有参数的size,则它就在template_defaults中。
顺便说一句如何去理解445行的”Not enough parameters to fill the template.”这个异常。如果我们有如下的语句
|
1 2 |
Query q = con.query(“select * from %9q”); q.store(“abc”); |
显然,在434行得到的num就是9,而实际上实参的size为1,且template_defaults.size为0,所以,这个时候显然就是”Not enough parameters to fill the template.”。
从449行开始到最后就是真正的填写参数的过程。
再来啰嗦一句,为什么要判一句if (param.is_null()),因为SQL中可以允许NULL,而C++的字符串的”NULL”和SQL的NULL的含义是不一样的,为了解决这个问题,MYSQL++提供了一个Null<T>类型,可以参看Null<T>的说明。如果我们需要在SQL语句中写入
|
1 |
select * from … where item = NULL |
这句话的含义完全不同于
|
1 |
select * from … where item = “NULL” |
为了让这种SQL NULL在template query中也可行,我们可以这样写
|
1 2 |
Query q = con.query(“select * from tblA where item = %0”” “); q.store(mysqlpp::null); |
再来说一下Query::pprepare(char option, SQLTypeAdapter& S, bool replace),为什么在处理非SQL NULL实参的时候需要经过这个函数过滤?因为我们还没有处理option呢,也就是”%xxxQ”中的这个Q(另外还有q,””等)。在这个函数中就是处理这些option,为该做escape和quote的地方按照要求决定是MYSQL++为调用者加(如果option是q,Q)还是无论如何都放弃(如果option是””)。当然,该方法也会把在形参(例如%xxxQ)之前的plain text也一同返回出来拼出一句合格的SQL语句。由于展开该方法会对主线有点偏离,所以大家可以自行看该函数的处理过程(在query.cpp中)。需要注意的是,在这个方法中可能会new出一些变量,需要在外面delete(例如456到460所示那样)。
最后来说一下什么是MYSQLPP_QUERY_THISPTR,这个宏真正的定义是#define MYSQLPP_QUERY_THISPTR dynamic_cast<std::ostream&>(*this)。
那么455行的MYSQLPP_QUERY_THISPTR << *ss;也就好追踪了。这个宏把Query对象给强制转换为其父类std::ostream,然后通过operator <<() 方法给*ss所代表的字符串放入自身的缓存。这个缓存其实就是sbuffer_,因为在Query的构造函数中就有对于ostream:: init(sbuffer_)的操作。
当这个proc()返回之后,就填写完了sbuffer_,随后就回到了那个non-template query的Query:: store()调用了。世界终于清静了……
好文章,内容欢风华丽.