多进程实现消费者生产者问题
一,实验目的
1,了解生产者消费者的互斥与同步问题
2,掌握Windows和Linux的进程通信方法
二,实验要求
完成Windows版本和Linux版本。
一个大小为3的缓冲区,初始为空。
2个生产者
随机等待一段时间,往缓冲区添加数据,
若缓冲区已满,等待消费者取走数据后再添加
重复6次
3个消费者
随机等待一段时间,从缓冲区读取数据
若缓冲区为空,等待生产者添加数据后再读取
重复4次
显示每次添加和读取数据的时间及缓冲区的状态
三,实验环境
Windows版本:Windows 10 64位系统,Dev-cpp编译器
Linux版本:Fedora29版本,gcc环境 vim文本编辑器
四,实验代码结构
1),pv操作伪代码:
array[3]:interger//缓冲区定义,大小为三
int empty=3,full=0;
int mutex=1;
i=0,j=0//缓冲区指针
x,y:item //产品变量
生产者: 消费者:
begin:
produce a product to x;
P(empty);
P(mutex);
array[i]=x;
ii=(i+1)%3;
V(full);
V(mutex);
,,,,,, ………,
End
消费者:

2)实验代码分析
Windows版本:
思路分析:Windows创建多进程使用creatprocess()函数调用自己,通过多次创建得到两个生产者进程三个消费者进程,在之中运行相应的生产者函数,消费者函数。在通过传入参数不同,来辨别是第一次主进程还是生产者进程,消费者进程。通过构建共享内存区进行进程间通信。
①多进程创建

② 构建共享内存区,再将文件映射到本进程,初始化

③在主创建进程间信号量full empty
![]()
分别在生产者消费者进程创建互斥访问量mutex
![]()
④同过argv量的不同判断进程归属
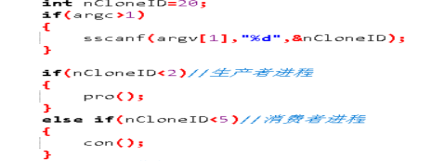
⑤运行结果:
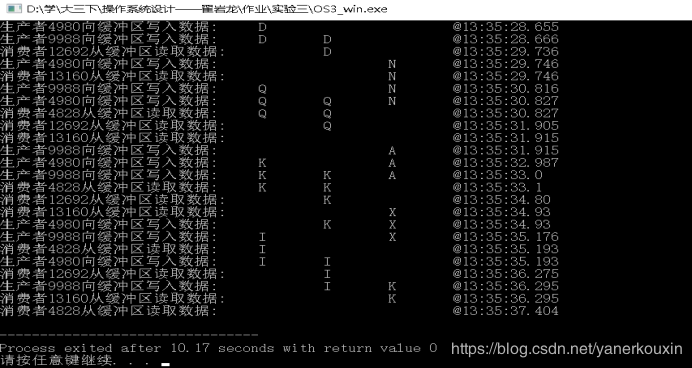
全部代码见后
Linux版本:
思路分析:Linux使用fork进行多进程创建,分别在进程中运行消费者函数,生产者函数。建立共享主存区很信号量在进程建进行通信和缓存访问

②建立共享主存并进行映射

③创建进程间信号量full,empty和互斥量 mutex,并初始化
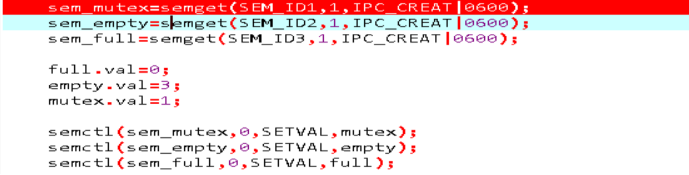
④实验结果:
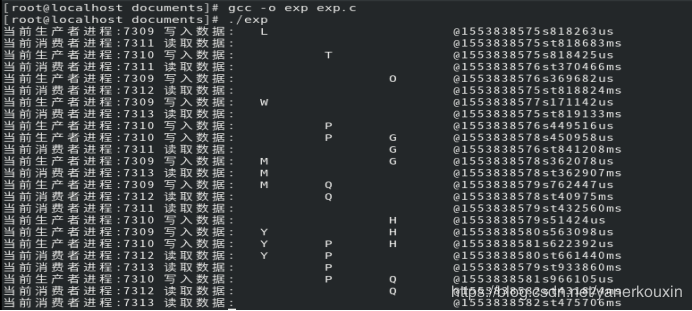
五, 实验总结
本次实验获得圆满成功。
本次实验通过分别编写Windows和Linux版本的多进程实现消费者和生产者问题,了解生产者消费者的互斥与同步问题,掌握Windows和Linux的进程通信方法,也同时加强自己对多进程操作的理解。
代码:
Windows版本:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 |
//实验三生产者消费者 #include <windows.h> #include <stdio.h> #include <time.h> HANDLE handleOfProcess[5]; struct buf { char buffer[3]; int write; int read; }; int rand_1() { return rand() % 100 + 1000; } char rand_char() { return rand() % 26 + 'A'; } void StartClone(int nCloneID) { TCHAR szFilename[MAX_PATH]; GetModuleFileName(NULL, szFilename, MAX_PATH); TCHAR szCmdLine[MAX_PATH]; sprintf(szCmdLine, "\"%s\" %d", szFilename, nCloneID); //printf("%s\n",szCmdLine); STARTUPINFO si; ZeroMemory(reinterpret_cast<void*>(&si), sizeof(si)); si.cb = sizeof(si); PROCESS_INFORMATION pi; BOOL bCreateOK = CreateProcess( szFilename, szCmdLine, NULL, NULL, FALSE, CREATE_DEFAULT_ERROR_MODE, NULL, NULL, &si, &pi); if (bCreateOK) handleOfProcess[nCloneID] = pi.hProcess; else { printf("Error in create process!\n"); exit(0); } } void pro()//生产者 { HANDLE mutex = CreateMutex(NULL, FALSE, "MYMUTEX"); HANDLE empty = OpenSemaphore(SEMAPHORE_ALL_ACCESS, FALSE, "MYEMPTY"); HANDLE full = OpenSemaphore(SEMAPHORE_ALL_ACCESS, FALSE, "MYFULL"); HANDLE hMap = OpenFileMapping(FILE_MAP_ALL_ACCESS, FALSE, "myfilemap"); LPVOID Data = MapViewOfFile(//文件映射 hMap, FILE_MAP_ALL_ACCESS, 0, 0, 0); struct buf* pint = reinterpret_cast<struct buf*>(Data); for (int i = 0; i < 6; i++) { WaitForSingleObject(empty, INFINITE); //sleep srand((unsigned)time(0)); int tim = rand_1(); Sleep(tim); WaitForSingleObject(mutex, INFINITE); //code pint->buffer[pint->write] = rand_char(); pint->write = (pint->write + 1) % 3; ReleaseMutex(mutex); ReleaseSemaphore(full, 1, NULL); SYSTEMTIME syst; time_t t = time(0); GetSystemTime(&syst); char tmpBuf[10]; strftime(tmpBuf, 10, "%H:%M:%S", localtime(&t)); printf("生产者%d向缓冲区写入数据:\t%c\t%c\t%c\t@%s.%d\n", (int)GetCurrentProcessId(), pint->buffer[0], pint->buffer[1], pint->buffer[2], tmpBuf, syst.wMilliseconds); fflush(stdout); } UnmapViewOfFile(Data);//解除映射 Data = NULL; CloseHandle(mutex); CloseHandle(empty); CloseHandle(full); } void con()//消费者 { HANDLE mutex = CreateMutex(NULL, FALSE, "MYMUTEX"); HANDLE empty = OpenSemaphore(SEMAPHORE_ALL_ACCESS, FALSE, "MYEMPTY"); HANDLE full = OpenSemaphore(SEMAPHORE_ALL_ACCESS, FALSE, "MYFULL"); HANDLE hMap = OpenFileMapping(FILE_MAP_ALL_ACCESS, FALSE, "myfilemap"); LPVOID Data = MapViewOfFile(//文件映射 hMap, FILE_MAP_ALL_ACCESS, 0, 0, 0); struct buf* pint = reinterpret_cast<struct buf*>(Data); for (int i = 0; i < 4; i++) { WaitForSingleObject(full, INFINITE); //sleep srand((unsigned)time(0)); int tim = rand_1(); Sleep(tim); WaitForSingleObject(mutex, INFINITE); pint->buffer[pint->read] = ' '; pint->read = (pint->read + 1) % 3; ReleaseMutex(mutex); ReleaseSemaphore(empty, 1, NULL); //code time_t t = time(0); char tmpBuf[10]; SYSTEMTIME syst; GetSystemTime(&syst); strftime(tmpBuf, 10, "%H:%M:%S", localtime(&t)); printf("消费者%d从缓冲区读取数据:\t%c\t%c\t%c\t@%s.%d\n", (int)GetCurrentProcessId(), pint->buffer[0], pint->buffer[1], pint->buffer[2], tmpBuf, syst.wMilliseconds); fflush(stdout); } UnmapViewOfFile(Data);//解除映射 Data = NULL; CloseHandle(mutex); CloseHandle(empty); CloseHandle(full); } int main(int argc, char* argv[]) { int nCloneID = 20; if (argc > 1) { sscanf(argv[1], "%d", &nCloneID); } if (nCloneID < 2)//生产者进程 { pro(); } else if (nCloneID < 5)//消费者进程 { con(); } else//主进程 { HANDLE hMap = CreateFileMapping( NULL, NULL, PAGE_READWRITE, 0, sizeof(struct buf), "myfilemap"); if (hMap != INVALID_HANDLE_VALUE) { LPVOID Data = MapViewOfFile(//文件映射 hMap, FILE_MAP_ALL_ACCESS, 0, 0, 0); if (Data != NULL) { ZeroMemory(Data, sizeof(struct buf)); } struct buf* pnData = reinterpret_cast<struct buf*>(Data); pnData->read = 0; pnData->write = 0; memset(pnData->buffer, 0, sizeof(pnData->buffer)); UnmapViewOfFile(Data);//解除映射 Data = NULL; } HANDLE empty = CreateSemaphore(NULL, 3, 3, "MYEMPTY"); HANDLE full = CreateSemaphore(NULL, 0, 3, "MYFULL"); for (int i = 0; i < 5; i++)//创建子进程 StartClone(i); WaitForMultipleObjects(5, handleOfProcess, TRUE, INFINITE); CloseHandle(empty); CloseHandle(full); } } |
Linux版本:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 |
//实验三:生产者消费者 #include<string.h> #include <sys/time.h> #include<stdio.h> #include<sys/types.h> #include<unistd.h> #include<stdlib.h> #include<sys/sem.h> #include<sys/select.h> #include<sys/wait.h> #include<sys/ipc.h> #include<sys/shm.h> #include<time.h> #define SEM_ID1 225 #define SEM_ID2 97 #define SEM_ID3 234 #define SHMKEY 75 struct buf { char buffer[3]; int read; int write; }; int rand_1() { return rand() % 300; } void sleep_ms(int s) { usleep(s * 10000); } char* cur_time() { time_t timep; time(&timep); return ctime(&timep); } char rand_char() { return rand() % 26 + 'A'; } void P(int s)//p操作 { struct sembuf sem_op; sem_op.sem_num = 0; sem_op.sem_op = -1; sem_op.sem_flg = 0; semop(s, &sem_op, 1); } void V(int s)//v操作 { struct sembuf sem_op; sem_op.sem_num = 0; sem_op.sem_op = 1; sem_op.sem_flg = 0; semop(s, &sem_op, 1); } void pro()//生产者 { int tim, shmid, i = 6; int sem_mutex, sem_empty, sem_full; void* addr; struct buf* pint; struct sembuf sem_op; struct timeval tv; sem_mutex = semget(SEM_ID1, 1, 0600); sem_empty = semget(SEM_ID2, 1, 0600); sem_full = semget(SEM_ID3, 1, 0600); shmid = shmget(SHMKEY, sizeof(struct buf), 0777); addr = shmat(shmid, 0, 0); while (i--) { gettimeofday(&tv, NULL); srand((unsigned)tv.tv_usec); tim = rand_1(); sleep_ms(tim); //P(empty) P(sem_empty); //P(mutex) P(sem_mutex); pint = (struct buf*)addr; // pint[semctl(sem_full,0,GETVAL)]=time; pint->buffer[pint->write] = rand_char(); pint->write = (pint->write + 1) % 3; printf("当前生产者进程:%d 写入数据:\t%c\t%c\t%c\t@%lds%ldus\n", getpid(), pint->buffer[0], pint->buffer[1], pint->buffer[2], tv.tv_sec, tv.tv_usec); //V(mutex) V(sem_mutex); //V(full) V(sem_full); } shmdt(addr); } void con()//消费者 { int tim, shmid, i = 4; int sem_mutex, sem_empty, sem_full; void* addr; struct buf* pint; struct sembuf sem_op; struct timeval tv; sem_mutex = semget(SEM_ID1, 1, 0600); sem_empty = semget(SEM_ID2, 1, 0600); sem_full = semget(SEM_ID3, 1, 0600); shmid = shmget(SHMKEY, sizeof(struct buf), 0777); addr = shmat(shmid, 0, 0); while (i--) { gettimeofday(&tv, NULL); srand((unsigned)tv.tv_usec); tim = rand_1(); sleep_ms(tim); //P(full) P(sem_full); //P(mutex) P(sem_mutex); pint = (struct buf*)addr; pint->buffer[pint->read] = ' '; pint->read = (pint->read + 1) % 3; printf("当前消费者进程:%d 读取数据:\t%c\t%c\t%c\t@%ldst%ldms\n", getpid(), pint->buffer[0], pint->buffer[1], pint->buffer[2], tv.tv_sec, tv.tv_usec); //V(mutex) V(sem_mutex); //V(empty) V(sem_empty); } shmdt(addr); } int main() { int sem_mutex, sem_empty, sem_full, shmid; void* addr; union semun { int val; }empty, full, mutex; //建立信号量 sem_mutex = semget(SEM_ID1, 1, IPC_CREAT | 0600); sem_empty = semget(SEM_ID2, 1, IPC_CREAT | 0600); sem_full = semget(SEM_ID3, 1, IPC_CREAT | 0600); full.val = 0; empty.val = 3; mutex.val = 1; semctl(sem_mutex, 0, SETVAL, mutex); semctl(sem_empty, 0, SETVAL, empty); semctl(sem_full, 0, SETVAL, full); //建立共享内存并进行映射 shmid = shmget(SHMKEY, sizeof(struct buf), 0777 | IPC_CREAT); if (-1 == shmid) { printf("建立共享内存失败\n"); exit(0); } addr = shmat(shmid, 0, 0); memset(addr, 0, sizeof(struct buf)); //执行生产者进程 for (int i = 0; i < 2; i++) if (fork() == 0) { pro(); exit(0); } //执行消费者进程 for (int i = 0; i < 3; i++) if (fork() == 0) { con(); exit(0); } while (-1 != wait(0)); semctl(sem_mutex, 0, IPC_RMID); semctl(sem_empty, 0, IPC_RMID); semctl(sem_full, 0, IPC_RMID); shmdt(addr); } |
近期评论