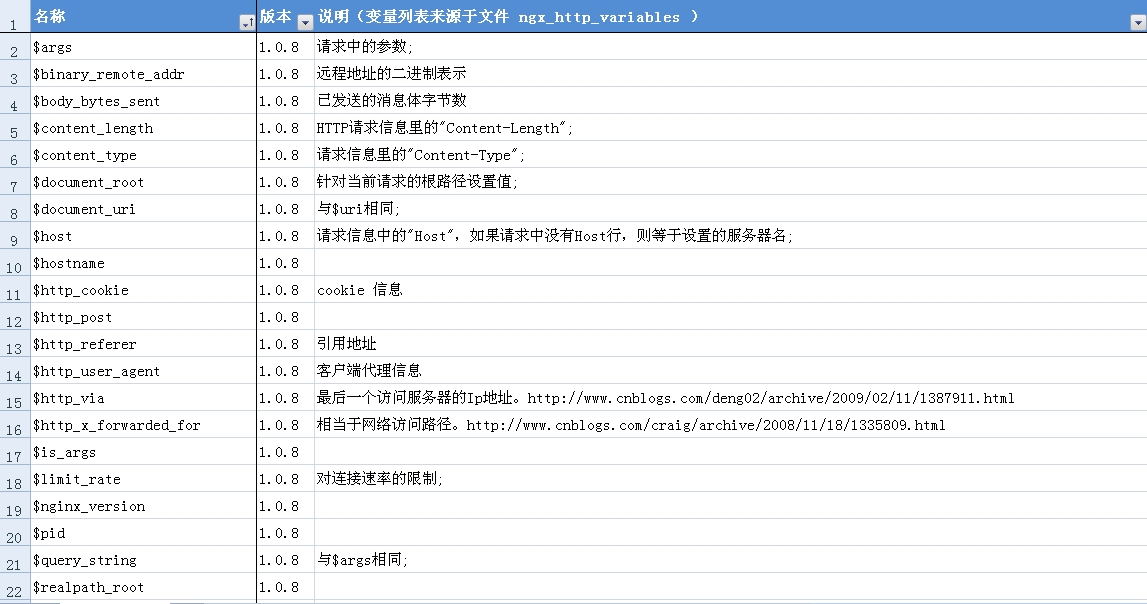
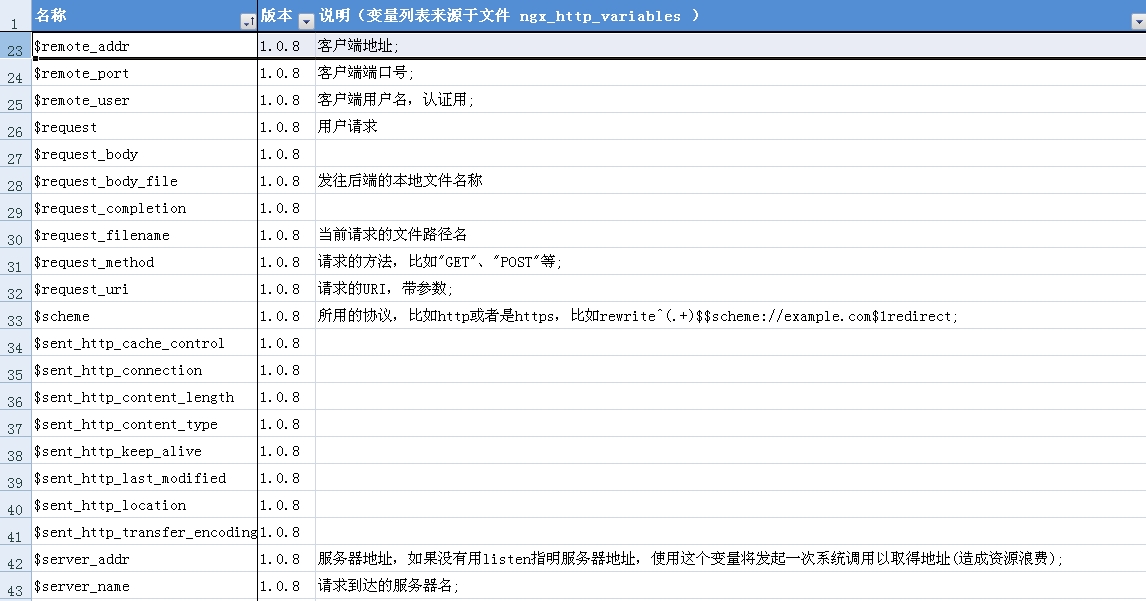
经常需要配置Nginx ,其中有许多以 $ 开头的变量,经常需要查阅nginx 所支持的变量。
可能是对 Ngixn资源不熟悉,干脆就直接读源码,分析出支持的变量。
Nginx支持的http变量实现在 ngx_http_variables.c 的 ngx_http_core_variables存储实现:
ngx_http_core_variables
static ngx_http_variable_t ngx_http_core_variables[] = {
{ ngx_string(“http_host”), NULL, ngx_http_variable_header,
offsetof(ngx_http_request_t, headers_in.host), 0, 0 },
{ ngx_string(“http_user_agent”), NULL, ngx_http_variable_header,
offsetof(ngx_http_request_t, headers_in.user_agent), 0, 0 },
{ ngx_string(“http_referer”), NULL, ngx_http_variable_header,
offsetof(ngx_http_request_t, headers_in.referer), 0, 0 },
#if (NGX_HTTP_GZIP)
{ ngx_string(“http_via”), NULL, ngx_http_variable_header,
offsetof(ngx_http_request_t, headers_in.via), 0, 0 },
#endif
#if (NGX_HTTP_PROXY || NGX_HTTP_REALIP)
{ ngx_string(“http_x_forwarded_for”), NULL, ngx_http_variable_header,
offsetof(ngx_http_request_t, headers_in.x_forwarded_for), 0, 0 },
#endif
{ ngx_string(“http_cookie”), NULL, ngx_http_variable_headers,
offsetof(ngx_http_request_t, headers_in.cookies), 0, 0 },
{ ngx_string(“content_length”), NULL, ngx_http_variable_header,
offsetof(ngx_http_request_t, headers_in.content_length), 0, 0 },
{ ngx_string(“content_type”), NULL, ngx_http_variable_header,
offsetof(ngx_http_request_t, headers_in.content_type), 0, 0 },
{ ngx_string(“host”), NULL, ngx_http_variable_host, 0, 0, 0 },
{ ngx_string(“binary_remote_addr”), NULL,
ngx_http_variable_binary_remote_addr, 0, 0, 0 },
{ ngx_string(“remote_addr”), NULL, ngx_http_variable_remote_addr, 0, 0, 0 },
{ ngx_string(“remote_port”), NULL, ngx_http_variable_remote_port, 0, 0, 0 },
{ ngx_string(“server_addr”), NULL, ngx_http_variable_server_addr, 0, 0, 0 },
{ ngx_string(“server_port”), NULL, ngx_http_variable_server_port, 0, 0, 0 },
{ ngx_string(“server_protocol”), NULL, ngx_http_variable_request,
offsetof(ngx_http_request_t, http_protocol), 0, 0 },
{ ngx_string(“scheme”), NULL, ngx_http_variable_scheme, 0, 0, 0 },
{ ngx_string(“request_uri”), NULL, ngx_http_variable_request,
offsetof(ngx_http_request_t, unparsed_uri), 0, 0 },
{ ngx_string(“uri”), NULL, ngx_http_variable_request,
offsetof(ngx_http_request_t, uri),
NGX_HTTP_VAR_NOCACHEABLE, 0 },
{ ngx_string(“document_uri”), NULL, ngx_http_variable_request,
offsetof(ngx_http_request_t, uri),
NGX_HTTP_VAR_NOCACHEABLE, 0 },
{ ngx_string(“request”), NULL, ngx_http_variable_request_line, 0, 0, 0 },
{ ngx_string(“document_root”), NULL,
ngx_http_variable_document_root, 0, NGX_HTTP_VAR_NOCACHEABLE, 0 },
{ ngx_string(“realpath_root”), NULL,
ngx_http_variable_realpath_root, 0, NGX_HTTP_VAR_NOCACHEABLE, 0 },
{ ngx_string(“query_string”), NULL, ngx_http_variable_request,
offsetof(ngx_http_request_t, args),
NGX_HTTP_VAR_NOCACHEABLE, 0 },
{ ngx_string(“args”),
ngx_http_variable_request_set,
ngx_http_variable_request,
offsetof(ngx_http_request_t, args),
NGX_HTTP_VAR_CHANGEABLE|NGX_HTTP_VAR_NOCACHEABLE, 0 },
{ ngx_string(“is_args”), NULL, ngx_http_variable_is_args,
0, NGX_HTTP_VAR_NOCACHEABLE, 0 },
{ ngx_string(“request_filename”), NULL,
ngx_http_variable_request_filename, 0,
NGX_HTTP_VAR_NOCACHEABLE, 0 },
{ ngx_string(“server_name”), NULL, ngx_http_variable_server_name, 0, 0, 0 },
{ ngx_string(“request_method”), NULL,
ngx_http_variable_request_method, 0,
NGX_HTTP_VAR_NOCACHEABLE, 0 },
{ ngx_string(“remote_user”), NULL, ngx_http_variable_remote_user, 0, 0, 0 },
{ ngx_string(“body_bytes_sent”), NULL, ngx_http_variable_body_bytes_sent,
0, 0, 0 },
{ ngx_string(“request_completion”), NULL,
ngx_http_variable_request_completion,
0, 0, 0 },
{ ngx_string(“request_body”), NULL,
ngx_http_variable_request_body,
0, 0, 0 },
{ ngx_string(“request_body_file”), NULL,
ngx_http_variable_request_body_file,
0, 0, 0 },
{ ngx_string(“sent_http_content_type”), NULL,
ngx_http_variable_sent_content_type, 0, 0, 0 },
{ ngx_string(“sent_http_content_length”), NULL,
ngx_http_variable_sent_content_length, 0, 0, 0 },
{ ngx_string(“sent_http_location”), NULL,
ngx_http_variable_sent_location, 0, 0, 0 },
{ ngx_string(“sent_http_last_modified”), NULL,
ngx_http_variable_sent_last_modified, 0, 0, 0 },
{ ngx_string(“sent_http_connection”), NULL,
ngx_http_variable_sent_connection, 0, 0, 0 },
{ ngx_string(“sent_http_keep_alive”), NULL,
ngx_http_variable_sent_keep_alive, 0, 0, 0 },
{ ngx_string(“sent_http_transfer_encoding”), NULL,
ngx_http_variable_sent_transfer_encoding, 0, 0, 0 },
{ ngx_string(“sent_http_cache_control”), NULL, ngx_http_variable_headers,
offsetof(ngx_http_request_t, headers_out.cache_control), 0, 0 },
{ ngx_string(“limit_rate”), ngx_http_variable_request_set_size,
ngx_http_variable_request_get_size,
offsetof(ngx_http_request_t, limit_rate),
NGX_HTTP_VAR_CHANGEABLE|NGX_HTTP_VAR_NOCACHEABLE, 0 },
{ ngx_string(“nginx_version”), NULL, ngx_http_variable_nginx_version,
0, 0, 0 },
{ ngx_string(“hostname”), NULL, ngx_http_variable_hostname,
0, 0, 0 },
{ ngx_string(“pid”), NULL, ngx_http_variable_pid,
0, 0, 0 },
{ ngx_null_string, NULL, NULL, 0, 0, 0 }
};
把这些变量提取下,总结如下:

近期评论